Agregiranje parcijalnih rang listi težina Escape roomova
TLDR
- Agregirao 1000 parcijalnih rang-listi escape roomova u jednu globalnu listu.
- Usporedio TrueSkill, GA i Bradley-Terry (BTL) u simulatoru s poznatim ground-truth poretkom.
- Evaluacija: Kendall τ kroz 100 ponavljanja.
- Najstabilniji: TrueSkill (≈0.90-0.93); GA ima veći plafon ali veću varijancu; BTL naivna verzija najnestabilnija.
Motivacija
Escape room je interaktivna soba puna zagonetki u kojoj je cilj pronaći sve tragove i pobjeći u najviše 60 minuta.
Bilo da ste početnik ili iskusniji igrač, korisno je znati koliko je soba teška. U slučaju da se prvi put iskušavate u rješavanju
zagonetki i odete u vrlo zahtjevnu sobu nećete se puno zabaviti, isto tako ako imate već puno soba iza sebe i odlučite se na sobu
namjenjenu za dječji uzrast nećete se previše zabaviti.
Zaključak: Svakome je cilj otići u sobu koja je točno na granici njihovih mogućnosti (kao i s mnogo drugih stvari u životu).
S toga bi bilo korisno da postoji rang lista koja obuhvaća sve sobe na koju se pojedinac može referirati prilikom donošenja odgovora na pitanje “Koju sobu posjetiti?”
Postoje rang liste na različitim forumima i blogovima, ali je problem što su subjektivne (mišljenje pojedinca) i nikada nisu potpune, odnosno ne uključuju sve sobe u nekom gradu ili državi.
 |  |  |
Problem
Ne postoji jedna rang lista koja sadrži sve sobe koja je nastala kao konsenzus više ljudi.
Cilj ovog projekta je bio osmisliti algoritam koji će objediniti više različitih parcijalnih rang listi u jednu konačnu rang listu.
Problem možemo formalizirati kao objedinjavanje (agregacija) parcijalnih rang-lista: iz više djelomičnih listi treba konstruirati jedinstvenu listu koja što bolje odražava stvarnu latentnu težinu svake sobe. Ova formulacija podsjeća na već poznate probleme rangiranja u teoriji preferencija, ali donosi i specifične izazove: podaci su škrti, postoji subjektivnost kod svakog ispitanika, sve sobe nisu jednako posjećene pa će samim time postojati nerazmjeran broj pojavljivanja popularnih i manje poznatih soba u rang listama te također pravi poredak nije izravno promatran.
Teorijski, pronalaženje optimalne agregirane rang liste prema Kemeny-Youngovom kriteriju dokazano je NP-težak problem. Stoga se, kao i u srodnim područjima kombinatorne optimizacije, okrećemo heuristikama i metaheuristikama koje u razumnom vremenu daju dovoljno dobra rješenja
Pregled korištenih metoda i izazovi
Problemu sam pristupio iz više kuteva, isprobao sam neke ustaljene metode za određivanje rang listi, jedan jednostavniji statistički model i naravno, genetski algoritam.
Klasični (i vrlo široko raširen) način procjene težine ili jačine je Elo sustav. Prvotno je smišljen za šah, ali se brzo proširio na mnoge druge zero-sum igre i općenito na rangiranja. Ideja je da svakom zadatku (u našem slučaju sobi) dodijelimo broj bodova, a kad igrač procijeni da je jedna soba teža od druge, bodovi se malo promijene. Zasniva se na odnosu između očekivanog i stvarnog ishoda. U krajnjim slučajevima, najveće promjene elo rejtinga će se dogoditi kada je očekivanje pozitivnog ishoda bilo gotovo sigurno, a dogodio se negativan ishod i obratno. Očekivanje ishoda se računa na temelju razlike u elo rejtingu.
Microsoftov TrueSkill je nadogradnja Elo sustava koja je zamišljena za kompleksnija okruženja s više igrača i većom nesigurnošću u procjeni ishoda. Dok je elo-rating idealan za 1 na 1 mečeve, TrueSkill je osmišljen za više igrača (u našem slučaju soba) što je bliže prirodi ovog problema. Osim procijene srednje vrijednosti težine sobe pratimo i standardnu devijaciju težine te sobe (koliko smo nesigurni u procjenu) što može biti korisno za manje popularne sobe. Također se bolje nosi s kontradiktornim listama koje se pojavljuju jer igrači mogu imati različita iskustva. To je zato što ne prati Luceov aksiom koji nalaže da relativne vjerojatnosti odabira jedne stavke u odnosu na drugu iz skupa mnogih stavki nisu pod utjecajem prisutnosti ili odsutnosti drugih stavki u skupu. Također za razliku od običnog Elo rejtinga, prilikom ažuriranja rejtinga se u obzir uzima i varijanca (nesigurnost u trenutni rejting)
Bradley-Terry (BTL) model parnih usporedbi je statistički model koji objedinjuje parcijalne rang-liste na temelju rezultata parnih usporedbi. Ideja je da modeliramo vjerojatnost da je jedan element iznad drugog pomoću funkcije razlike njihovih latentnih vrijednosti. Konkretno, tretirali bi sve rangirane parove kao opažanja i naučili latentne vrijednosti tako da najbolje objašnjavaju sve parne usporedbe.
Naravno, kako je riječ o NP-teškom problemu probao sam i metaheuristički pristup, konkretno koristeći genetski algoritam. Genetski algoritam stvara populaciju mogućih listi, križa ih i mutira te zadržava one koje bolje odgovaraju izvornim podacima. Također bi se algoritmi poput simuliranog kaljenja mogli pokazati dobri za ovaj problem. Poredak bi se predstavio kao permutacijska lista, ciljna funkcija kao broj nepodudaranja s parcijalnim rang-listama, a susjedstvo kao zamjena dvaju elemenata u listi. Ovo rješenje bi vjerojatno bilo vrlo dobro kada bi imali veliki broj lista (npr. ocjenjivanje na svjetskoj razini) jer se dobro nosi s velikim brojem elemenata i konfliktima među rang-listama, ali ga nećemo koristi jer definirani problem nema tako velik skup podataka.
Escape Roomovi donose nekoliko posebnih problema:
- Malo podataka - ista ekipa rijetko odigra mnogo različitih soba (gotovo uvijek manje od pola), pa je matrica usporedbi vrlo rijetka.
- Različita popularnost soba - nisu sve sobe jednako popularne, ako se vodimo prema broju ocjena na TripAdvisoru, neke sobe imaju tisuće ocjena dok neke samo 50ak što je razlika za dva reda veličine. Ovo implicira da će neke sobe biti na vrlo malom broju rang-listi pa će samim time biti teže odrediti njihovu konačnu poziciju.
- Pristranost igrača - ekipa sklona logičkim zagonetkama može smatrati sobu lakšom nego ekipa koja preferira fizičke zadatke. Osim toga postoje i drugi faktori koji doprinose subjektivnom osjećaju poput naspavanosti, stresa…
- Promjene tijekom vremena - razina vještine nije konstanta već monotono raste s brojem posjećenih soba. Ovo može rezultirati time da igrači sobu koju su posjetili ranije u svojoj karijeri ocijene težom od druge jednako zahtjevne sobe koju su posjetili kasnije.
Simulator za testiranje kvalitete rješenja
Budući da nemamo pravu rang listu za usporedbu, pokušao sam što vjernije simulirati proces prikupljanja podataka kako bih mogao usporediti različite metode agregacije rang lista.
Simulator omogućava generiranje velikog broja umjetnih parcijalnih rang-listi koje imitiraju stvarne uvjete ocjenjivanja soba od strane igrača. Svaka parcijalna rang-lista generira se uzimajući u obzir popularnost pojedinih soba, subjektivnost pojedinih igrača te njihovu razinu iskustva koja uvjetuje percepciju težine soba.
Prilikom generiranja parcijalnih rang-listi primjenjuje se Gaussova distribucija kako bi se simulirala subjektivnost i različite razine iskustva korisnika. Osim toga, primijenjena je metoda ponderiranog odabira bez ponavljanja za simulaciju popularnosti pojedinih soba.
Kvaliteta objedinjene rang-liste evaluira se pomoću Kendallovog τ koeficijenta korelacije s unaprijed poznatim točnim poretkom soba. Simulator prihvaća različite funkcije za objedinjavanje rang-listi, što omogućuje lako testiranje i uspoređivanje različitih heurističkih optimizacijskih postupaka i pristupa temeljenih na strojnom učenju.
Kako nastaje jedna parcijalna rang lista igrača u simulatoru
- Koliko soba igrač rangira?
Za svakog igrača broj soba koje je posjetio nasumično se generira iz normalne distribucije sa srednjom vrijednošću 4 i standardnom devijacijom 2.5, rezultat se zaokruži i ograniči na barem 1, a najviše na broj svih soba. Ovak pristup simulira činjenicu da broj soba koje je pojedini igrač posjetio nije isti, ali je za očekivati da takav broj dolazi iz normalne distribucije. - Koje sobe ulaze u uzorak?
Nisu sve sobe jednako popularne. Što je neka soba popularnija, to je vjerojatnije da će ju simulator odabrati. Time kopiramo “bias tržišta”: atraktivne ili reklamirane sobe češće će se pronaći u parcijalnim rang-listama igrača te za ovu čenjenicu moramo kompenzirati u algoritmima, nastojeći da takve sobe nemaju prednost prilikom agregacije u konačnu rang listu. - Idealni poredak prema istini
Kad je podskup odabran, simulator ga prvo posloži točno onako kako stoji u simulatoru poznatoj ground-truth listi. Naknadno se dodaje subjektivnost, ali je za očekivati da će većina igrača svoje rang-liste kreirati približno slično objektivnoj istini. - Ubrizgavanje osobne pristranosti
Niti jedan igrač ne prosuđuje savršeno. Zato se kroz ljestvicu jednom prođe i svaki susjedni par može zamijeniti mjesta. Što je osobni bias veći, to je ta vjerojatnost veća. Rezultat je kratka rang-lista koja većinom slijedi istinu, ali ima pokoju lokalnu grešku, baš kao i stvarni blog post ili komentar na forumu.
Takva lista naziva se parcijalni rang, jer pokriva samo dio soba i samo približno redoslijedom kako zaista jesu. Simulatoru kažemo da ponovi gornji postupak primjerice 1000 puta. Svaki put novi igrač donosi vlastitu, djelomičnu i pristranu listu. Dobivamo veliku kolekciju razbacanih mišljenja sasvim poput pravog slučaja gdje se recenzije gomilaju na različitim stranicama mjesecima.
Algoritam za agregaciju kojeg testiramo dobije isključivo te parcijalne liste. On iz njih mora kreirati konačnu rang-listu svih soba. Kad algoritam završi i vrati tu listu, simulator je uspoređuje s ground-truth-om pomoću Kendallova τ koeficijenta:
- τ = 1 → podudara se savršeno
- τ ≈ 0 → jedva bolji od slučajnog pogađanja
- τ = -1 → poredak je potpuno obrnut
Tako svaki agregator dobije jasan broj od -1 do 1 kojim se mjeri njegova točnost.
Rezultat
Za svrhu usporedbe ovih algoritama eksperiment je ponovljen 100 puta: generirano je 1000 parcijalnih lista težine escape-soba, proslijeđene svakom od triju algoritama i za svaku dobivenu globalnu listu izmjerena je uspješnost Kendallovim τ prema skrivenoj ground-truth ljestvici.
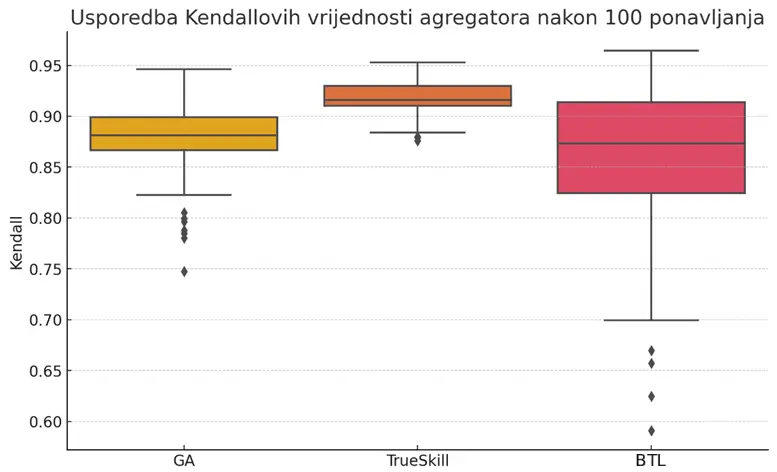
Kutija TrueSkilla gotovo je spljoštena, većina vrijednosti zbijena je u uski raspon između 0.90 i 0.93, dok se gornji i donji brk jedva protežu izvan tog okvira. Može se zaključiti da ovaj model radi gotovo jednako dobro u svakom ponavljanju. Razlog je što TrueSkill svakoj sobi pripisuje distribuciju težine i ažurira je pri svakom opažanju. Tako ne gubi iz vida nesigurnost i ne skače naglo kad podaci nisu savršeni. U praksi to znači da čak i kada slučajnost promijeni uzorak parcijalnih lista, procjene završe na gotovo istome mjestu.
Genetski algoritam pokazuje medijan nešto slabiji od TrueSkilla, no njegova kutija i brkovi znatno su viši. Ponekad doseže vrhunce od 0.95, a ponekad pada na 0.82 uz povremene outliere oko 0.75. Ovo je za očekivati zbog nasumične prirode heuristike. Većina populacija pogodi smjer prema optimalnom poretku, ali povremeno se dogodi da zaglavi u lokalnom optimumu ili prerano izgubi genetsku raznolikost. GA prema tome nudi visoki plafon, ali ne garantira konzistentnost odličnih rezultata.
Treći stupac BTL logističkog modela pokazuje još širu kutiju i brkove, s medijanom oko 0.86 i repom koji tone do 0.60. Ovaj model se pokazao najlošiji što je za očekivati jer je korištena naivna verzija modela koja pretpostavlja da su parne usporedbe homogene i neovisne što ovdje nije slučaj zbog postojanja šuma koji unosi subjektivnost. Postupak kojeg koristi ovaj model je brz i elegantan, ali pretjerano vjeruje da se u podacima ne krije sustavna pristranost ni praznine. Kada se dogodi da isti par soba rijetko nastupi ili da bias igrača preokrene očekivani ishod, optimizacija lako zastane daleko od optimuma. Ovaj model služi kao dobra početna točka, ali bez dodatne regularizacije ili većeg broja parova ostaje najnestabilniji.